
Cloud : Superviser les logs systèmes et applicatifs avec Prometheus sur Ubuntu
Pré-requis et temps pour tester ce mode opératoire
- 1 serveur / VM Ubuntu LTS
- 1 VM Ubuntu via VirtualBox/Multipass/WSL.
- 1 à 2 heures de votre temps (1h pour ceux qui connaissent Prometheus, 2 pour les autres)
Déployer Prometheus et la Push gateway
Cela ce fait avec APT :
# apt install prometheus prometheus-pushgateway Configurer Prometheus pour pour superviser la pushgateway
Dans le fichier de configuration de Prometheus, dans le hash scrape_configs, ajouter :
# vi /etc/prometheus/prometheus.yml [...]
- job_name: pushgateway
static_configs:
- targets: ['localhost:9091']
[...]Redémarrer Prometheus
# systemctl restart prometheus
Vérifier que la Push Gateway et Prometheus fonctionne
via une tunnel local en CLI :
# ssh -L 9091:localhost:9091 connect_user@mon_serveur Via Putty, soit avant de se connecter ,
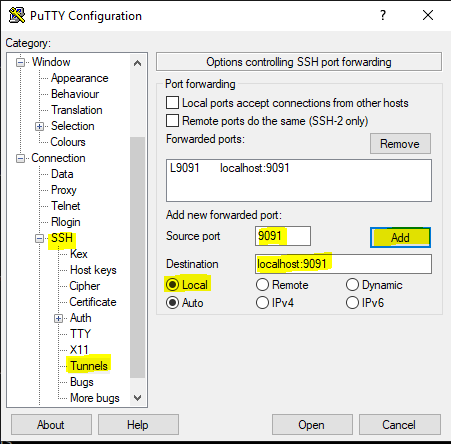
soit ensuite, en cliquant sur l’icône en haut à gauche de Putty et en choisissant le menu 'Change Settings'
Sur mRemoteNG en cliquant sur l'onglet d'un shell ouvert et choisissant : 'Paramètres de PUTTY'
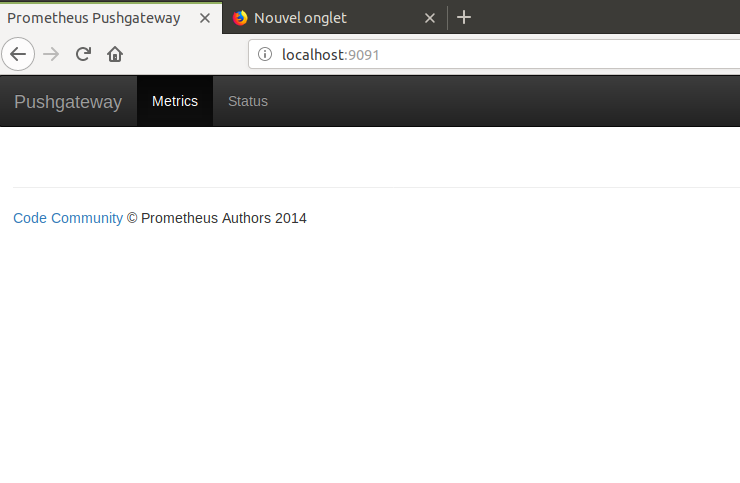
Ensuite il suffira d'aller sur le navigateur de votre ordinateur sur l'adresse http://localhost:9091
Vous devez obtenir un IHM comme celle-ci.
Ensuite refaite le même type de tunnel sur le port 9090 pour Prometheus et connectez-vous sur l'url http://localhost:9090, vous devriez obtenir une IHM tel que :
Cliquez sur status, puis target vous devriez trouver un IHM comme celle-ci, vérifier la présence de pushgateway en status UP
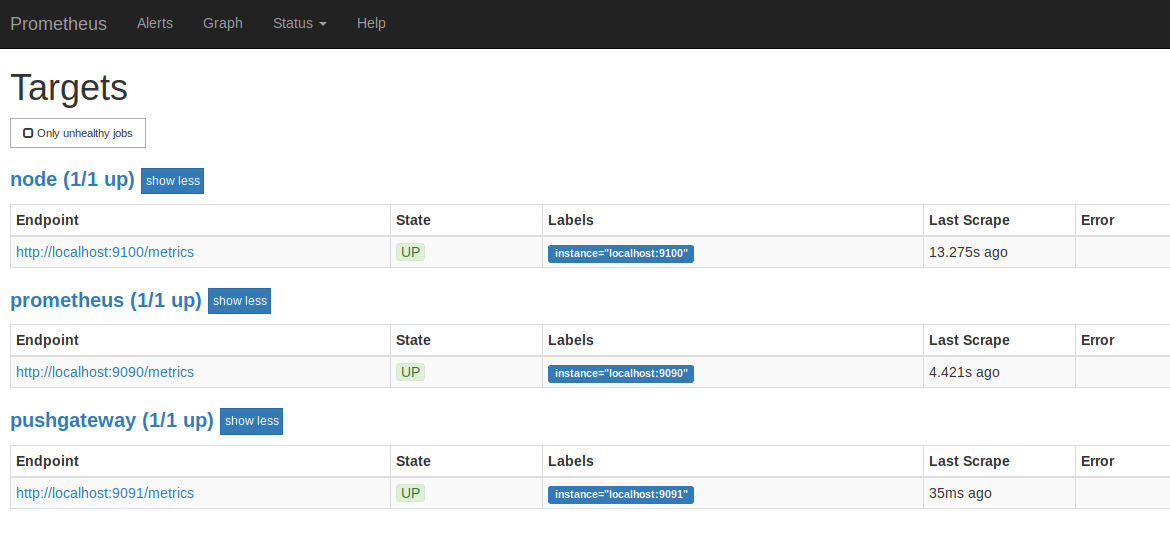
Remarque : Node peut ne pas être configurer, cela n'est pas grave pour notre usecase.
Prometheus est installé et configuré.
Installation de Prometheus-splash
il va être nécessaire d'installer et configurer Ruby
# apt install ruby ruby-dev une fois cette étape faite, installez Prometheus-splash
# gem ins prometheus-splash --no-ri --no-rdoc Remarque :Les options--no-riet--no-rdocservent à ne pas installer la doc développeur mais n’empêche pas d'avoir la doc utilisateur cela accélère fortement l'installation.
Une fois la package installé il faut initialiser Splash
# splash conf set
Splash -> setup :
* Installing Configuration file : /etc/splash.yml : [OK]
👍 Splash Initialisation
👍 Installing template file : /etc/splash_execution_report.tpl
👍 Creating/Checking pid file path : /var/run/splash
👍 Creating/Checking trace file path : /var/run/splash/traces :
💪 Splash Setup terminated successfullyCela initialise Splash, mais c'est optionnel, Splash est capable de détecter si il n'est pas initialisé et s'initialise lui-même dès la première exécution.
ℹ️ Remarque :splash conf setest la forme abrégée desplash config setup, splash supporte les abréviations de commandes tant qu'il peu discriminer deux commandes, au pire il le dira.
⚠️ Attention : relancer cette commande sans l'option --preserve réinitialise le fichier de configuration de Splash.
Pour connaitre les commandes ou sous commandes il suffit de taper splash sans commande :
# splash
Commands:
splash commands SUBCOMMAND ...ARGS # Managing commands/batchs supervision & orchestration
splash config SUBCOMMAND ...ARGS # Config tools for Splash
splash daemon SUBCOMMAND ...ARGS # Splash daemon controller
splash documentation SUBCOMMAND ...ARGS # Documentation for Splash
splash help [COMMAND] # Describe available commands or one specific command
splash logs SUBCOMMAND ...ARGS # Managing Files/Logs supervision
splash processes SUBCOMMAND ...ARGS # Managing processes supervision
splash sequences SUBCOMMAND ...ARGS # Managing Sequences of commands
splash transfers SUBCOMMAND ...ARGS # Managing transfers
splash webadmin SUBCOMMAND ...ARGS # Splash Webadmin daemon controller
Options:
-q, [--quiet], [--no-quiet] # Quiet mode, limit output to :fatal
[--emoji], [--no-emoji] # Display Emoji
# Default: true
[--colors], [--no-colors] # Display colors
# Default: true
-d, [--debug], [--no-debug] # Set log level to :debug ou par exemple avec un sous-commande pour listes ses actions :
# splash config
Commands:
splash config flushbackend # Flush configured backend
splash config help [COMMAND] # Describe subcommands or one specific subcommand
splash config sanitycheck # Verify installation fo Splash
splash config service # Install Splashd Systemd service
splash config setup # Setup installation fo Splash
splash config version # Display current Splash versionPour vérifier que tout est opérationnel, il suffit de taper :
# splash conf san
ℹ️ Splash -> sanitycheck :
👍 Config file : /etc/splash.yml
👍 PID Path : /var/run/splash
👍 Trace Path : /var/run/splash/traces
👍 Prometheus PushGateway Service running
💪 Splash Sanitycheck terminated successfullyConfiguration du monitoring des logs
Exemple : /var/log/syslog
On veut monitorer le log système en détectant le nombre de lignes matchant la regexp /ERROR/
pour cela on va modifier la configuration de Splash dans le fichier de configuration /etc/splash.yml
# vi /etc/splash.yml
[...]
>>>>> a supprimer
### Sample configuration of monitored logs
:logs:
- :label: :log_app_1
:log: /tmp/test
:pattern: ERROR
:retention:
:hours: 5
- :label: :log_app_2
:log: /tmp/test2
:pattern: ERROR
:retention:
:hours: 5
-----
:logs:
- :label: :syslog
:log: /var/log/syslog
:pattern: ERROR
:retention:
:day: 1
<<<<<< a ajouter
[...]ℹ️ Remarque : la clef retention est optionnel, elle indique l'historique des traces de Splash et ne représente pas la rétention de la TSDB de Prometheus
ℹ️ Remarque : Splash supporte la pluralisation on peux donc écrire la rétention en [ :days, :day, :hours, :hour ] ⚠️ Attention : le label est un symbol (Ruby) et donc les ':' devant la chaine sont obligatoire
Test de monitoring
Via la ligne de commande on vérifie que le log est bien configuré :
# splash logs list
ℹ️ Splash configured log monitoring :
🔹 log monitor : /var/log/syslog label : syslogEnsuite on peut avoir le détail d'un log record :
# splash log show syslog
ℹ️ Splash log monitor : /var/log/syslog
🔹 pattern : /ERROR/
🔹 label : syslogPour lancer une analyse des logs configurés on tape :
# sudo splash log analyse
ℹ️ SPlash Configured log monitors :
👍 Log : /var/log/syslog with label : syslog : no errors
🔹 Detected pattern : ERROR
🔹 Nb lines = 17728
👍 Global status : no error found
Pour lancer le monitoring vers Prometheus Push Gateway :
# splash log mon
ℹ️ Sending metrics to Prometheus Pushgateway
👍 File Backend folder : /var/run/splash/logs created
👍 Sending metrics for log /var/log/syslog to Prometheus PushgatewayLes métriques sont envoyées vers la Push Gateway on peut le constater sur http://localhost:9091

On clique sur le Job="splash"
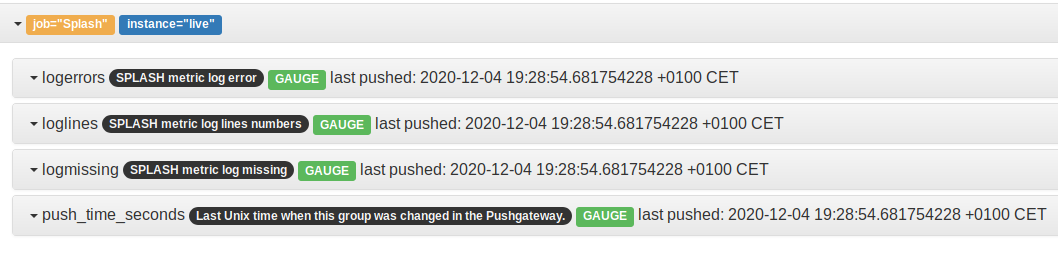
On voit que 3 métriques sont disponibles
logerrors : le nombre d'occurence de la regexp matchée => pour faire de la détection de motif
- loglines : le nombre de ligne du log => pour détecter du mass increase ou un pbm de rotation de log
- logmissing un bouléen : pour checker l'absence du log
Si on clique sur une des métriques on voit la valeur instantanée.

On peu lister (modulo rétention) toutes les itérations de splash log monitor :
# splash log history syslog --table 
Vérification dans Prométheus
sur http://localhost:9090 :
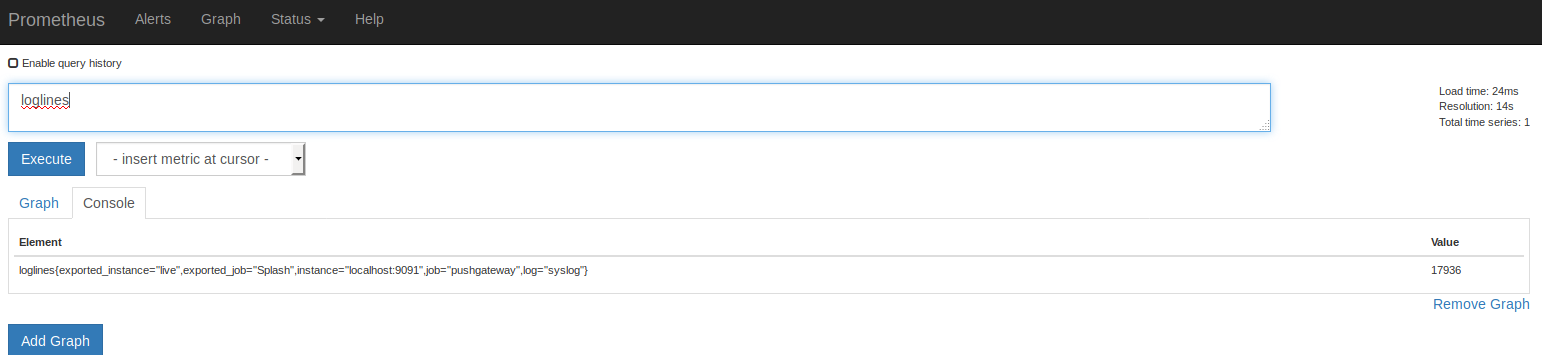
on recherche par exemple loglines
on trouve une occurrence dans la TSDB :
loglines{exported_instance="live",exported_job="Splash",instance="localhost:9091",job="pushgateway",log="syslog"} Cela veut dire et ce qui est important :
- metric : loglines : le type de métrique
- exported_instance : live => le nom de la machine
- log : syslog le label su log surveillé (il faut donc choisir un label explicite)
la value est un integer qui représente le nombre de lignes du log
On pourra suivre les graphes pour cette métrique :
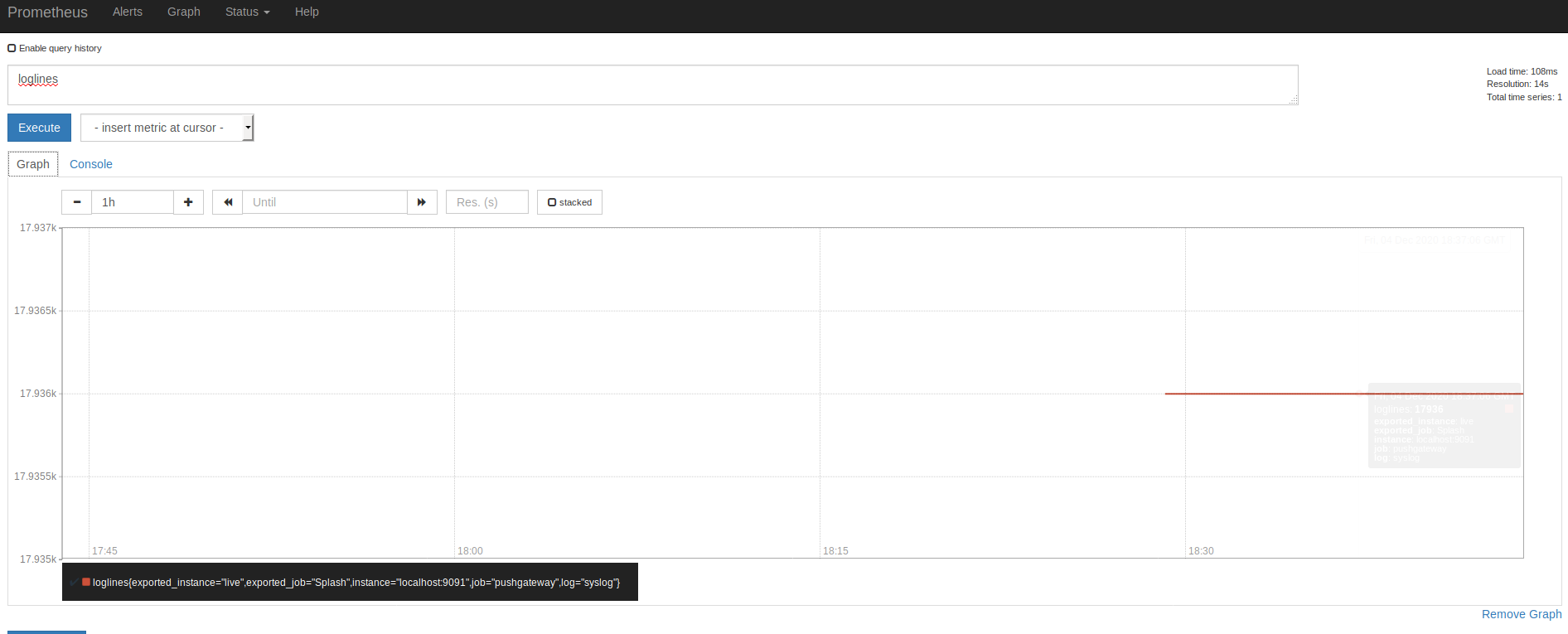
Pour logmissing :
on trouve une occurrence dans la TSDB :
logmissing{exported_instance="live",exported_job="Splash",instance="localhost:9091",job="pushgateway",log="syslog"} Cela veut dire et ce qui est important :
- metric : logmissing : le type de métrique
- exported_instance : live => le nom de la machine
- log : syslog le label su log surveillé (il faut donc choisir un label explicite)
la value est un booleen qui veut dire
- 0 => log présent
- 1 => log absent
Pour logerrors :
on trouve une occurrence dans la TSDB :
logerrors{exported_instance="live",exported_job="Splash",instance="localhost:9091",job="pushgateway",log="syslog"}
Cela veut dire et ce qui est important :
- metric : logerrors : le type de métrique
- exported_instance : live => le nom de la machine
- log : syslog le label su log surveillé (il faut donc choisir un label explicite)
la value est un integer qui représente le nombre de match du motif (en l'occurence ERROR) dans le log
Utilisation en production
Pour lancer le monitoring :
- Soit, si on utilise que cette fonction de Splash ( splash intègre un Scheduler, un ordonnanceur de commandes/batch ou de séquences, un module de tranferts de fichiers SFTP monitorés, une interface Web, un monitoring de processus) on peu le lancer via CRON en lançant sur la crontab root une ligne du type :
/usb/bin/env splash logs mon - Soit Splash fournit via son scheduler un moyen de lancer le monitoring automatiquement pour ce faire il faut lancer le daemon Splashd avec une configuration à adapter aux besoins :
# vi /etc/splash.yml :splash:
### Main Configuration
:paths:
:pid_path: /var/run/splash
:trace_path: /var/run/splash/traces
:loggers:
:level: :info
:daemon:
:file: /var/log/splash.log
:cli:
:emoji: true
:color: true
:templates:
:execution:
:path: /etc/splash_execution_report.tpl
:backends:
:stores:
:execution_trace:
:type: :file
:path: /var/run/splash/executions
# :execution_trace:
# :type: :redis
# :host: localhost
# :port: 6379
# #:auth: "mykey"
# :base: 1
:transfers_trace:
:type: :file
:path: /var/run/splash/transfers
:logs_trace:
:type: :file
:path: /var/run/splash/logs
:process_trace:
:type: :file
:path: /var/run/splash/process
:transports:
:active: :rabbitmq
:rabbitmq:
:vhost: /
:port: 5672
:host: localhost
# :passwd: testpasswd
# :user: test
:daemon:
:logmon_scheduling:
:every: 20s
:metrics_scheduling:
:every: 15s
:procmon_scheduling:
:every: 20s
:process_name: "Splash : daemon."
:files:
:stdout_trace: stdout.txt
:stderr_trace: stderr.txt
:pid_file: splash.pid
:prometheus:
:pushgateway: 'http://localhost:9091'
:url: 'http://localhost:9090'
:alertmanager: 'http://localhost:9093'
:webadmin:
:port: 9234
:ip: 127.0.0.1
:proxy: false
:process_name: "Splash : WebAdmin."
:files:
:stdout_trace: stdout_webadmin.txt
:stderr_trace: stderr_webadmin.txt
:pid_file: splash_webadmin.pid
:commands:
:logs:
- :label: :syslog
:log: /var/log/syslog
:pattern: ERROR
:retention:
:day: 1
### configuration of monitored processes
:processes:
## Sample configuration of executions sequences
:sequences:
### Transfers
:transfers:
###Il faut adapter les lignes en gras, mais les valeurs par défaut sont suffisantes pour un usage direct.
ℹ️ Remarque : Si on utilise que le log monitoring il est souhaitable de supprimer les données des autres fonctions, tel que dans l'exemple.
ℹ️ Remarque : pour une usage en production il est nécessaire de changer les paths dans /var/cache pour qu'il soit persistant au reboot.
⚠️ Attention : pour que le daemon puisse fonctionner il lui faut une dépendance supplémentaire : RabbitMQ, soit votre projet en à un en place, soit vous pouvez le déployer pour l'exemple, via docker ou via :
# apt install rabbitmq-server ⚠️ Attention : en production il faudra le sécuriser et donc adapter la configuration par défaut de Splash tel que :
- # vi /etc/splash.yml
[...]
:transports:
:active: :rabbitmq
:rabbitmq:
:vhost: votre vhost
:port: 5672
:host: votre host
:passwd: votre password
:user: votre user
[...]Ensuite, pour lancer le daemon il faut taper :
# splash daemon start
ℹ️ Queue : splash.live.input purged
👍 Splash Daemon Started, with PID : 17343
💪 Splash Daemon successfully loaded.
- le controller supporte les actions :
- stop
- start
- status
Le daemon Splashd loggue sur /var/log/splash.log par défaut :
[2020-12-04T20:14:44+01:00] (18457) INFO : Splash Orchestrator starting :
[2020-12-04T20:14:44+01:00] (18457) ITEM : Initializing Sequences & commands Scheduling.
[2020-12-04T20:14:44+01:00] (18457) ITEM : Initializing logs monitorings & notifications.
[2020-12-04T20:14:44+01:00] (18457) ITEM : No processes to monitor
[2020-12-04T20:14:44+01:00] (18457) ITEM : Initializing Splash metrics notifications.
[2020-12-04T20:14:59+01:00] (18457) (1607109284115) TRIGGER : Splash Metrics monitoring for Scheduling : every 15s
[2020-12-04T20:14:59+01:00] (18457) (1607109284115) OK : Sending Splash self metrics to PushGateway.
[2020-12-04T20:15:05+01:00] (18457) (1607109305546) TRIGGER : Logs monitoring for Scheduling : every 20s
[2020-12-04T20:15:05+01:00] (18457) (1607109305546) INFO : Sending metrics to Prometheus Pushgateway
[2020-12-04T20:15:05+01:00] (18457) (1607109305546) OK : Sending metrics for log /var/log/syslog to Prometheus Pushgateway
......le process Splash se recherche via :
# ps aux|grep Splash
root 18457 0.4 5.1 711440 105696 pts/0 Sl 20:14 0:01 Splash : daemon.Installer Splashd dans Systemctl
Pour installer Splashd comme un service et qu'il soit lancé au démarrage du système , il faut executer :
# splash conf service
# systemctl enable splashd Déploiement d'Alertmanager
On install avec APT via :
# apt install prometheus-alertmanager Raccordement Prometheus vers Alertmanager
On édite le fichier de configuration de Prometheus pour ajouter le lien :
# vi /etc/prometheus/prometheus.yml [...]
alerting:
alertmanagers:
- scheme: http
static_configs:
- targets:
- "localhost:9093"
[...]Puis on restart Prometheus
# systemctl restart prometheus On fait un tunnel local sur le port 9093
# ssh -L 9093:localhost:9093 osadmin@serveur (voir chapitre sur configuration Putty Plus haut)
On se connect via le tunnel sur son navigateur : http://localhost:9093
Ajout d'une règle pour detecter un nombre de ligne trop important sur un log
On réédite les fichiers de configuration de Prometheus, on ajoute dans rule_files:
# vi /etc/prometheus/prometheus.yml [...]
rule_files:
- "/etc/prometheus/log.rules.yml"
[...]
On ajoute un fichier /etc/prometheus/log.rules.yml :
# vi /etc/prometheus/logs.rules.yml groups:
- name: logs.rules
rules:
##############################
- alert: log_too_many_lines
for: 30s
expr: loglines > 10
labels:
object_class: SUP_LOG
type: Logs
annotations:
severity: CRITICAL
env: TEST
instance: " {{ $labels.exported_instance }}"
state: oversized
alertname: "Too many lines in log in {{ $labels.log }}"
description: "Too many lines in log in {{ $labels.log }} nb lines : {{ $value }}"👆 Remarque : Cette règle n'est pas destinée à la PRODUCTION, un log de 10 lignes reste relativement rare. 😉
La règle dit : " si un des logs fait plus de 10 pendant plus de 30s alors je lève une alerte de classe DK_LOG et de type Logs"
Test de la règle
👆 Remarque : si vous avez lancé un demon et que votre config surveille bien le /var/log/syslog, il est quasi certain que vous avez une alerte qui "Brûle"
Sinon, configurez la surveillance de ce log, comme présenté plus haut et taper la commande suivante pour forcer le monitoring :
# splash log mon
ℹ️ Sending metrics to Prometheus Pushgateway
👍 Sending metrics for log /var/log/syslog to Prometheus PushgatewayEnsuite consulter l'IHM de Prometheus dans le menu Alerte, en cliquant sur l'alerte, vous devriez y trouver : (si vous êtes très rapide, - de 30s, il se peut qu'elle soit en jaune (PENDING)):
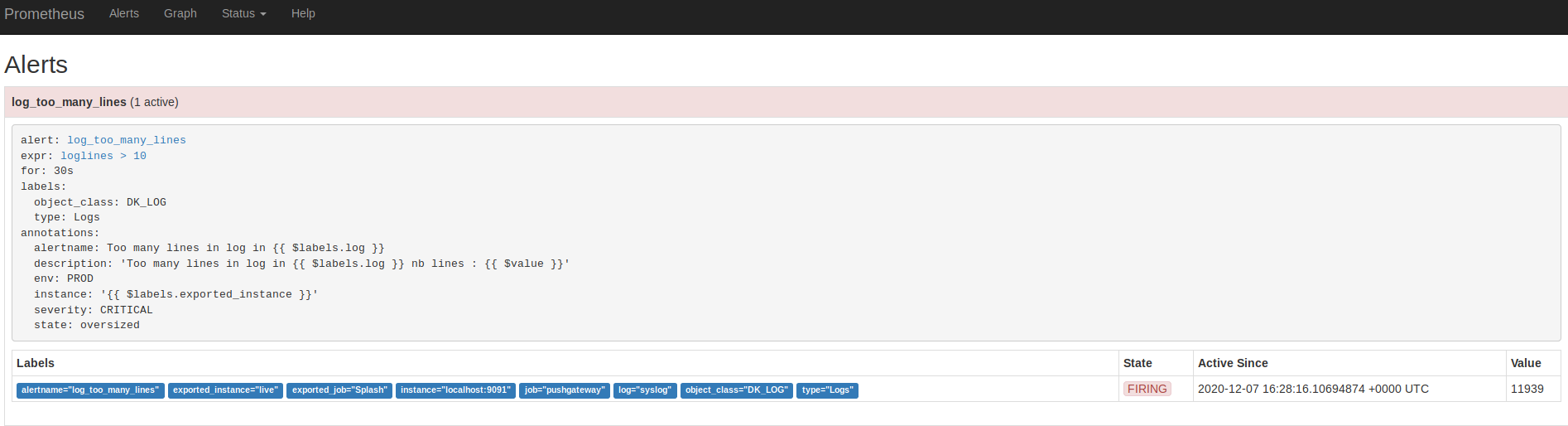
Configuration pour test de Alertmanager

Remarque : En PRODUCTION, on va utiliser Alertmanager via Webhook sur la BEM ou via mattermost, nous allons donc tester une sortie Webhook.
🛟 Tips : Pour tester ou pour débogguer ses alertes je vous présente une solution simple, un webhook en localhost vers un Dumper de requête POST simple
Dans un deuxième Terminal on va ajouter une commande dans sa home en ajoutant le fichier suivant :
# cd
# vi get.rb =>
require 'sinatra'
require 'json'
post "/trace" do
content_type :text
File.open('./trace.txt','w') do |w|
w.puts JSON.pretty_generate( JSON.load(request.body.read))
end
end on le lance via (comme Splash est installé sur la machine toutes les dépendances de cet outil son installées) :
# ruby get.rb
= Sinatra (v2.1.0) has taken the stage on 4567 for development with backup from Thin
Thin web server (v1.7.2 codename Bachmanity)
Maximum connections set to 1024
Listening on localhost:4567, CTRL+C to stopLe processus ne rendra pas la main c'est normal : ouvrez encore un autre terminal pour consulter les traces.
⚠️ Attention : on regarde le port en gras car il faudra le reproduire dans la conf de test
On remplace toute la configuration de Alertmanager par une nouvelle version :
# vi /etc/prometheus/alertmanager.yml global:
smtp_smarthost: 'localhost:25'
smtp_from: 'root@localhost'
resolve_timeout: 20s
route:
repeat_interval: 20s
receiver: 'test'
receivers:
- name: 'test'
webhook_configs:
- url: 'http://localhost:4567/trace'On redémarre Alertmanager :
# systemctl restart prometheus-alertmanager On va sur l'IHM Alertmanager, on doit trouver :
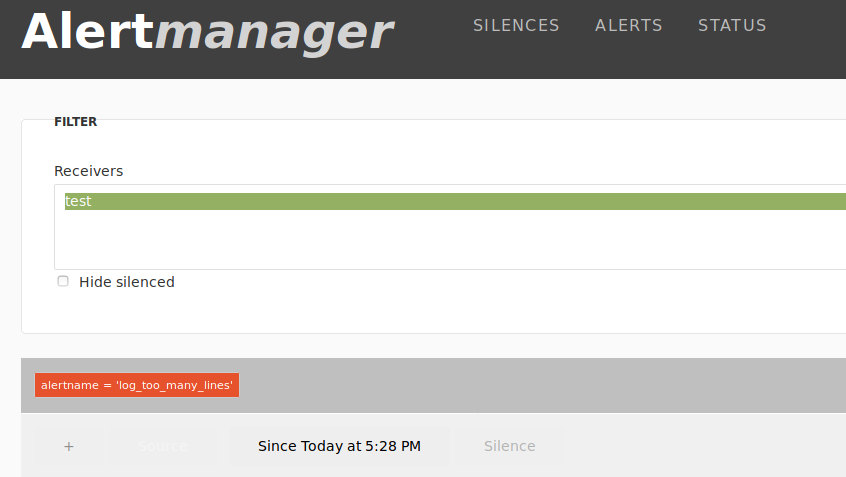
Normalement sur le shell du ruby get.rb
vous devriez trouver un ligne du type :
::1 - - [07/Dec/2020:17:45:01 +0100] "POST /trace HTTP/1.1" 200 - 0.0014Sinon redémarrez Prometheus pour qu'il rebrule l'alarme :
# systemctl restart prometheus Si la ligne est présente cela veut dire que le Webhook à bien été activé et donc faite :
# cat ~/trace.txt on obtient une sortie du genre ( la partie en gras nous interresse )=>
{
"receiver": "test",
"status": "firing",
"alerts": [
{
"status": "firing",
"labels": {
"alertname": "log_too_many_lines",
"exported_instance": "live",
"exported_job": "Splash",
"instance": "localhost:9091",
"job": "pushgateway",
"log": "syslog",
"monitor": "example",
"object_class": "OB_LOG",
"type": "Logs"
},
"annotations": {
"alertname": "Too many lines in log in syslog",
"description": "Too many lines in log in syslog nb lines : 11939",
"env": "TEST",
"instance": "live",
"severity": "CRITICAL",
"state": "oversized"
},
"startsAt": "2020-12-07T17:28:46.109658483+01:00",
"endsAt": "0001-01-01T00:00:00Z",
"generatorURL": "http://live:9090/graph?g0.expr=loglines+%3E+10&g0.tab=1"
}
],
"groupLabels": {
"alertname": "log_too_many_lines"
},
"commonLabels": {
"alertname": "log_too_many_lines",
"exported_instance": "live",
"exported_job": "Splash",
"instance": "localhost:9091",
"job": "pushgateway",
"log": "syslog",
"monitor": "example",
"object_class": "SUP_LOG",
"type": "Logs"
},
"commonAnnotations": {
"alertname": "Too many lines in log in syslog",
"description": "Too many lines in log in syslog nb lines : 11939",
"env": "TEST",
"instance": "live",
"severity": "CRITICAL",
"state": "oversized"
},
"externalURL": "http://live:9093",
"version": "4",
"groupKey": "{}:{alertname=\"log_too_many_lines\"}"
}c'est ce qui démontre que notre alerte fonctionne bien et qu'elle peut router vers autre chose par la suite (chatops, webhook, etc ...)
Les Rules pour la PRODUCTION
Pour exploiter les trois métrciques voici des exemples de rules
On ajoute un fichier /etc/prometheus/log.rules.yml :
# vi /etc/prometheus/logs.rules.yml groups:
- name: logs.rules
rules:
##############################
- alert: log_too_many_lines
for: 30s
expr: loglines > 100000
labels:
object_class: SUP_LOG
type: Logs
annotations:
severity: CRITICAL
env: PROD
instance: " {{ $labels.exported_instance }}"
state: oversized
alertname: "Too many lines in log in {{ $labels.log }}"
description: "Too many lines in log in {{ $labels.log }} nb lines : {{ $value }}"
##############################
- alert: error_in_log
for: 30s
expr: logerrors > 0
labels:
object_class: SUP_LOG
type: Logs
annotations:
severity: CRITICAL
env: PROD
instance: " {{ $labels.exported_instance }}"
state: matched
alertname: "Error(s) found in log {{ $labels.log }}"
description: "Error(s) found in log {{ $labels.log }} nb errors : {{ $value }}"
##############################
- alert: log_missing
for: 30s
expr: logmissing > 0
labels:
object_class: SUP_LOG
type: Logs
annotations:
severity: CRITICAL
env: PROD
instance: " {{ $labels.exported_instance }}"
state: missing
alertname: "Log is missing : {{ $labels.log }}"
description: "Log is missing : {{ $labels.log }}"👆 Remarque : il peut être souhaitable de faire des rules moins génériques dans laquelle la requête PromQL intègre un log en particulier ou une exported_instance spécifique, cela s'écrit par exemple pour loglines :
expr: loglines{log=syslog} > 100000
expr: loglines{log=syslog, exported_instance=serveur} > 100000