Kubernetes ? une visite « guidée…. À thème »
Parler de Kubernetes et présenter Kubernetes c’est comme visiter le Louvres !


On peut pas tout visiter en une journée ! Sauf qu’on ne peut pas faire une visite limitée à une partie sans avoir fait un premier survol.
Ce que nous allons faire aujourd’hui.

Vidéo précédante

Principe base : détail du modèle descriptifs de Kubernetes
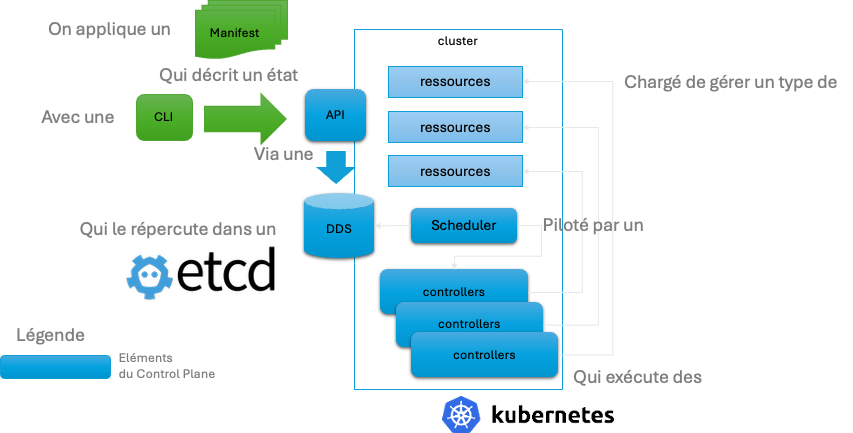
Impératif vs descriptif
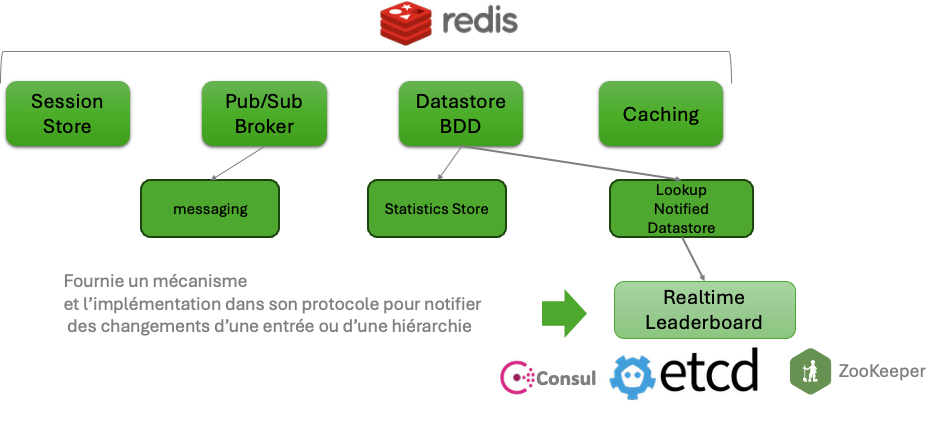
Un mot sur les distributed datastores : notamment etcd
Les DDS sont des bases NoSQL
Du type key-value et/ou représentation par arbre
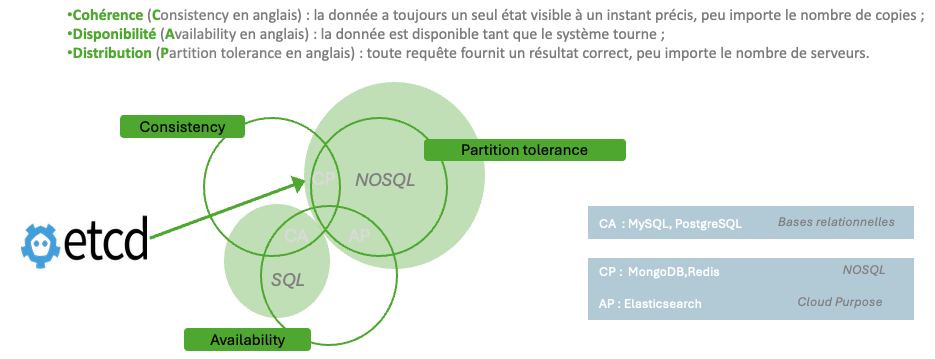
CAP & Théoreme de Brewer
Ou se positionne etcd ?
Selon le théorème de CAP, dans toute base de données, vous ne pouvez respecter au plus que 2 propriétés parmi la cohérence, la disponibilité et la distribution.
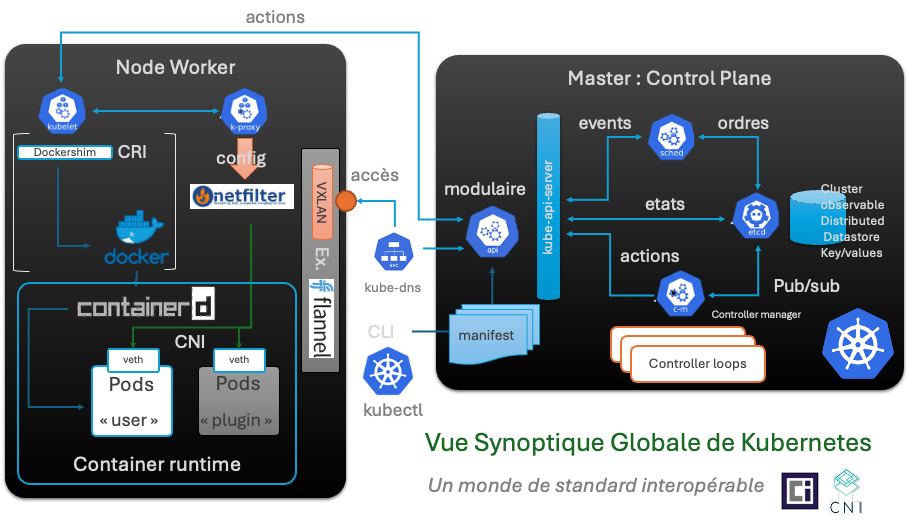
Glossaire phase 1 : Le Control Plane
Le Control Plane en lui-même
le Control Plane Kubernetes est composé de plusieurs éléments. Chacun de ces éléments sont essentiels à la bonne santé d’un cluster Kubernetes. Si un de ces composants vient à dysfonctionner le cluster devient instable voir irrécupérable (etcd par exemple).
Le Control Plane n’est pas un serveur mais peut se distribuer et se scaler sur plusieurs serveurs, certaines fonctions du Control plane peuvent être des containers
ETCD
ETCD est une base de données distribuée de type clé-valeur, qui a été développée en “Go”, le langage de programmation de Google. Dans un cluster Kubernetes, ETCD est chargé de stocker la configuration et les informations nécessaires au fonctionnement du cluster, c’est-à-dire de tous ses composants : les nœuds, les pods, les configs, les secrets, les rôles, les comptes, etc.
L’API-Server
L'API Server est le composant central du cluster qui expose l'API REST de Kubernetes. C’est donc l’élément “frontal” du Control Plane de Kubernetes et c’est lui qui reçoit tous les appels et demandes, externes ou internes.
Le Scheduler
Le scheduler est chargé de la répartition des pods entre les différents workers nodes. Cette répartition se fait en fonction des ressources disponibles et des contraintes qui lui sont indiquées. Ces contraintes peuvent être des prérequis de type CPU et mémoire, des contraintes hardware, des affinités et anti-affinités.
Les nœuds sont filtrés en supprimant ceux qui ne répondent pas aux exigences du pod. Ensuite, les nœuds retenus sont classés par score, celui ayant obtenu le score le plus élevé est sélectionné.
Le scheduler indique au service kubelet du worker node sélectionné qu’il doit démarrer le pod.
Le Controller-Manager
Dans Kubernetes, le Controller Manager contient plusieurs controllers. Un controller est une boucle de contrôle qui surveille en permanence l’état d’un groupe d’objet qui lui est attribué. Il fera des demandes de modifications au serveur d’API, ou en direct si nécessaire, pour que l’état actuel de ses objets soit celui de l’état souhaité.
Glossaire phase 2 : Les nodes
kubelet
Kubelet est un agent qui tourne sur tous les worker nodes du cluster Kubernetes. Kubelet examine les spécifications qui lui sont transmises par le scheduller et fait en sorte que les conteneurs définis avec ces spécifications tournent et soient en bonne santé.
kube-proxy
kube-proxy est un proxy réseau qui s’exécute sur chaque worker node de du cluster et gère les règles réseau. Ces règles réseau permettent une communication réseau vers les Pods depuis des sessions réseau à l’intérieur ou à l’extérieur du cluster. kube-proxy utilise la couche de filtrage de paquets du système d’exploitation hôte s’il y en a une de disponible. Sinon, kube-proxy transmet le trafic lui-même.
Container Runtime
L’environnement d’exécution de conteneurs (Container Runtime) est le logiciel responsable de l’exécution des conteneurs. Le CRI est une interface de plug-in qui permet à kubelet d’utiliser différents environnements d’exécution de conteneurs, sans à avoir besoin de recompiler les composants du cluster. Kubernetes est compatible avec : Docker, ContainerD, cri-o, rktlet entre autres.
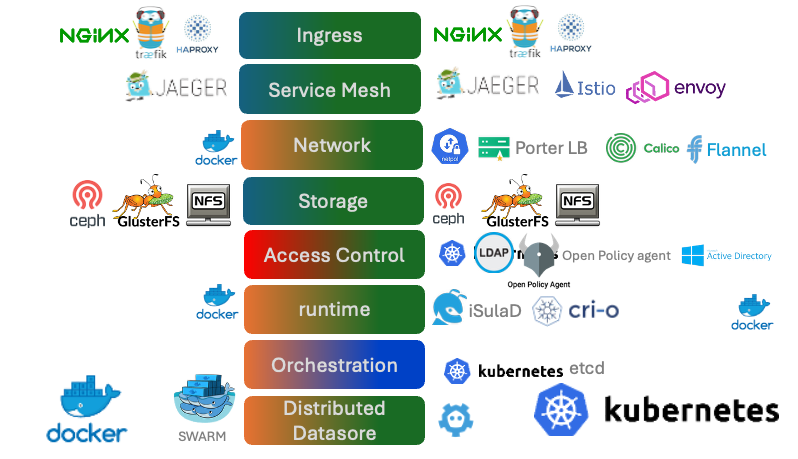
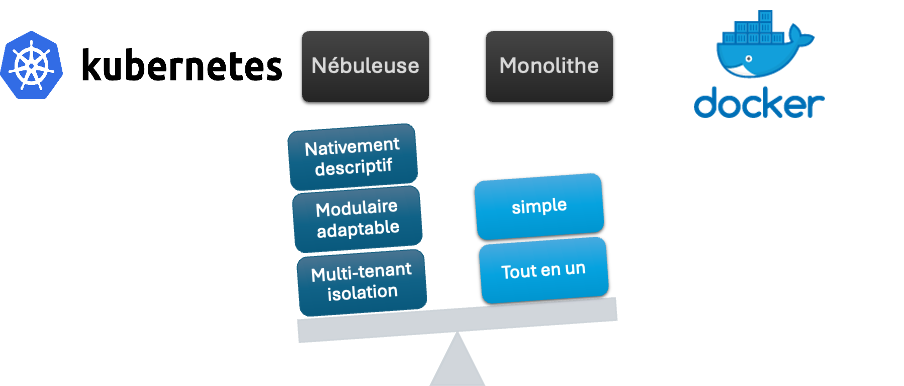
Monolith vs Modular
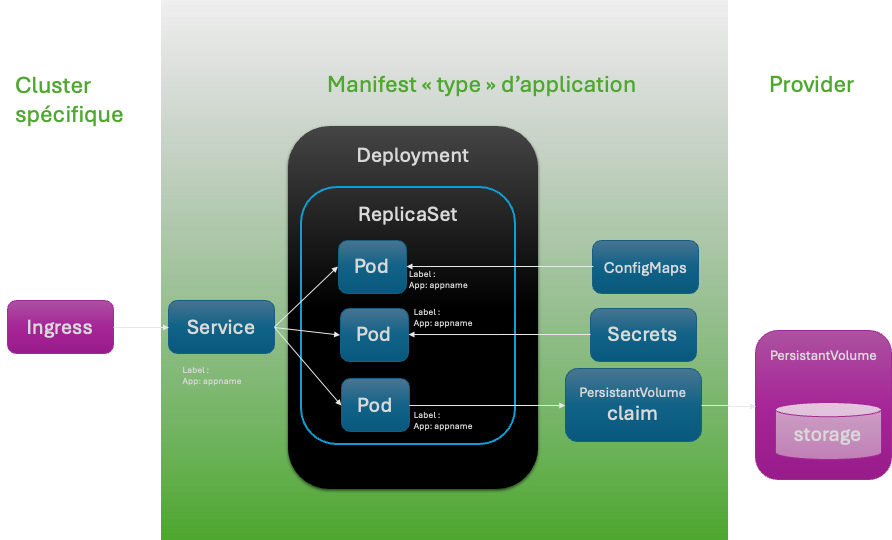
Le schéma « qui pique »
Les ressources de base
Centrique sur les matchSelectors
- Le cloud est un monde volatile
- Le cloud est un monde de méta-données
Le cycle de vie d’un Pod est dépendant de l’activité du cluster et de contraintes. Il faut donc un moyen de gérer l’aspect non persistant et volatile d’un Pod
Il faut voir :
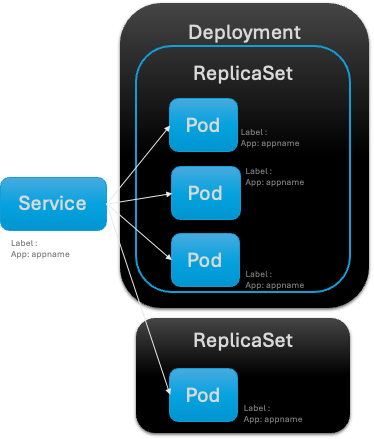
- Le ReplicaSet comme un contrat
- Le déployment comme la définition d’un template de contrat identifié par des labels
Le service se bind sur le « contrat » d’exécution, le ReplicaSet par un matchSelector, ex : Tout les Pod qui on App == appname
Glossaire phase 3 : Les Ressources Kubernetes
Namespaces
Dans Kubernetes, les namespaces ou espaces de noms fournissent un mécanisme pour isoler des groupes de ressources au sein d’un seul cluster. Les noms de ressources doivent être uniques au sein d’un même namespace, mais pas entre namespaces.
Pods
Les pods sont les plus petites unités déployables que vous pouvez créer et gérer dans Kubernetes. Un Pod est un groupe d’un ou plusieurs conteneurs partageant des ressources réseau, de stockage et d’un ensemble d’espaces de noms qui s’exécutent sur les workers.
Services
Comme les pods sont des objets non permanents comment y accéder si leur IP changent ? C’est à ce niveau qu’interviennent les Services. Un service est une couche d’abstraction qui définit des règles permettant d’accéder à un ensemble logique de pods. Un Service permet donc aux pods de recevoir du trafic.
Volumes
Par défaut les fichiers d’un pod sont éphémères, lorsqu’un conteneur plante, kubelet va le redémarrer, mais les fichiers du pod précédent sont perdus.
Pour ajouter de la persistance de données dans kubernetes il est possible d’utiliser des volumes. Kubernetes prend en charge plusieurs types de stockage dont les principaux sont : hostPath, emptyDir, configMap, nfs, secret, local, PersistentVolumeClaim, …
L’Ingress et le service
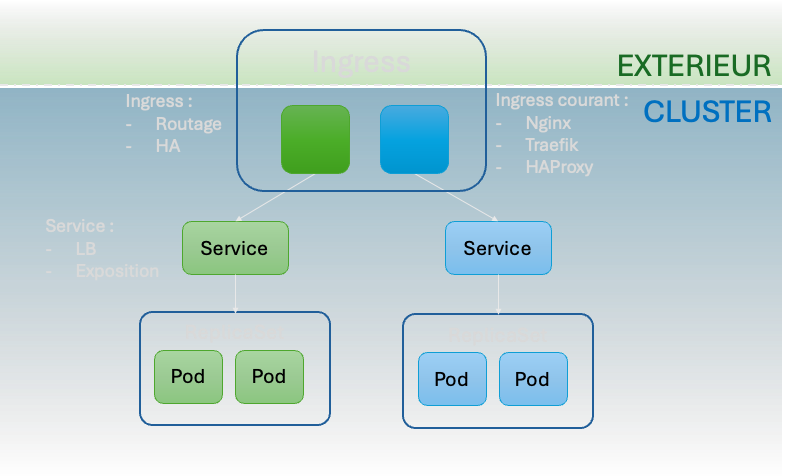
Contrats particuliers
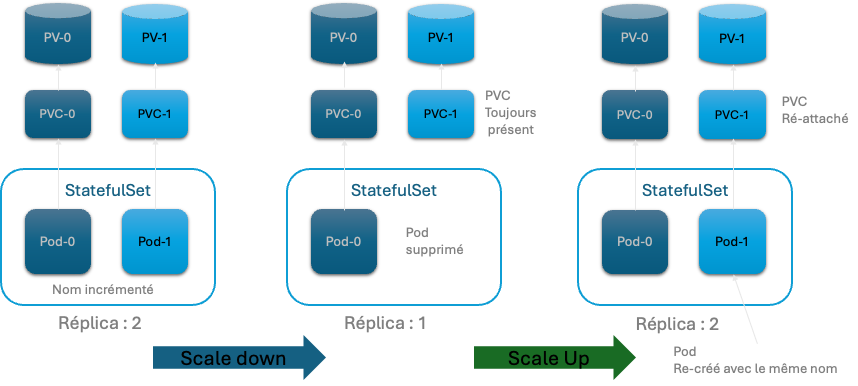
StatefulSet
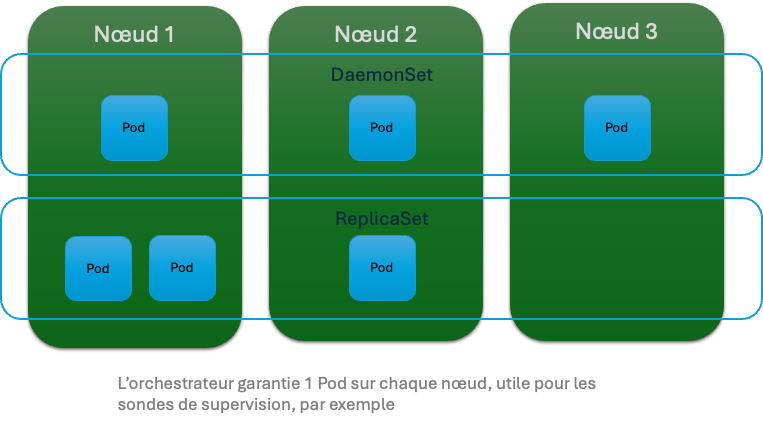
DaemonSet
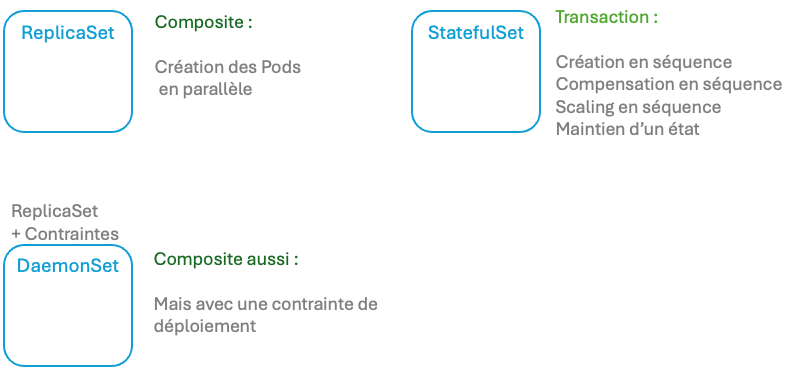
Synthèse
Glossaire phase 4 : les Workloads
Un Work-quoi ?
Un workload (charge de travail) est une application fonctionnant sur Kubernetes faisant appel à un ou à une série de pods. Un workload Kubernetes permet d’automatiser le processus de publication d’une application et de la rendre ainsi reproductible. Tout est géré par le back-end de Kubernetes sans intervention de votre part, sauf bien sur sa déclaration.
ReplicaSet
Un contrat passé avec l’orchestrateur pour assurer un Réplica de Pods durant la durée d’application d’un Workload
Déployments
Un déploiement permet de décrire le cycle de vie d’une application sans état, en spécifiant en autre les images à utiliser, la façon dont les pods doivent être mis à jour ou mis à l’échelle (scaling)
StatefulSet
Contrairement à un déployment, un StatefulSet conserve une identité persistante pour chacun de ses pods. Les pods d’un StatefulSet sont créés à partir de la même spécification, mais ne sont pas interchangeables : chacun a un identifiant persistant qu’il conserve lors de toute reconstruction.
DaemonSet
Le DaemonSet est utilisé pour le déploiement, comme son nom l’indique d’un daemon. Il va lancer une instance unique de pod sur chacun des workers nodes du cluster Kubernetes. En cas d’ajout d’un worker node, le controle plane de Kubernetes va programmer l’ajout d’un Pod pour ce DaemonSet sur ce nouveau noeud.
On l’utilise le plus souvent pour gérer du stockage, du monitoring ou de la journalisation de log.
Jobs et CronJobs
Les Jobs permettent d’exécuter des tâches ponctuelles voir des batchs plus complets. CronJob, en analogie avec les crons linux, permet de planifier à quels moments (minute, heure, jour du mois, mois et jour de la semaine) ces tâches doivent s’exécuter.
Asynchronismes et Jobs
CronJobs & Jobs
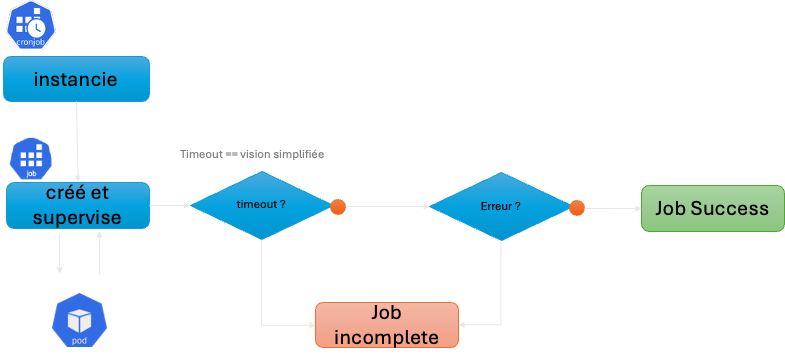
Le rollin’ deployment / rollout et le scaling
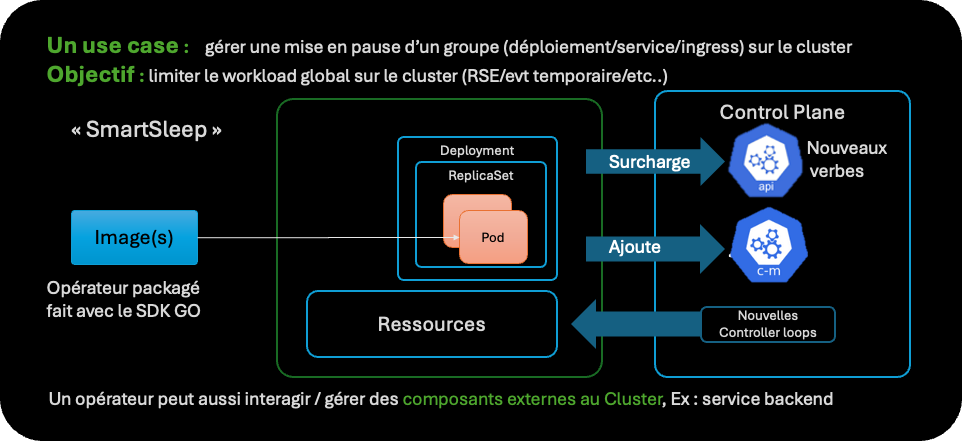
Aspect modulaire de Kubernetes, les opérateurs
Ajout de ressource Kubernetes et de boucles de contrôle
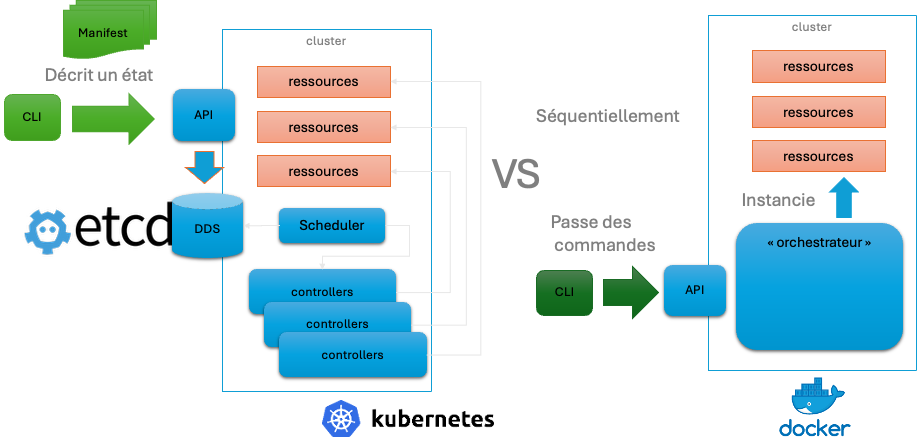
Kubernetes vs Swarm
Les liens utiles

Open your source, des guides pas-à-pas très bien fait, sur les outils du DevOps et notamment sur Kubernetes
